On our current project we practise continuous integration and we perform weekly releases.
To simplify the decision whether a particular build is fit for production we introduced a release candidate report that contains all the information that we usually take into account as well as instructions on how to interpret this information. In this article I describe how we came to this point.
The classical view of the build process is that it takes a defined version of the source code and ideally deterministically produces executable artifacts.
With the advent of pervasive automated testing the focus has shifted from only producing “binaries” to actually validating any given version of the software. There are static analysis steps that assert syntactic correctness (compiler) and adherence to coding standards (e.g. lint, checkstyle) and there is dynamic testing of units and the overall system for functional and non-functional quality.
Traditionally automated tests are self-validating, i.e. they evaluate the outcome to either passing or failing – green or red:
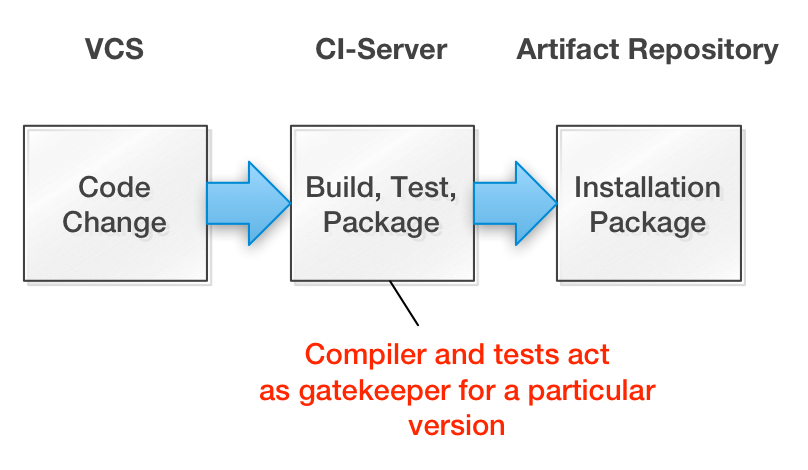
They should be passing or failing deterministically, because computers are deterministic machines after all. At least that’s the theory. Anyone who has done serious test automation knows that concurrency issues can lead to non-deterministic test results.
Bugs aside we have however observed a class of tests that produce output that defies staright forward automatic validation. The first reason is that the test returns a metric that has more than one dimension, e.g. precision and recall in an information retrieval system or latency and throughput for load tests. Secondly the tests may be based on current user behaviour, which makes tests more realistic, but less comparable. An example would be a load test that always uses the latest production traffic patterns or a quality metric that uses user feedback. In a similar vain “cloud-based” architectures with a lot network connections and virtual machines have highly non-deterministic performance characteristics.
Also, there is the case of tests where the outcome is hard to evaluate for a machine, e.g. validating the layout of a web page by comparing it to the previous version. Here tools can assist, but as of today the human brain is much more powerful at understanding whether a layout has been broken.
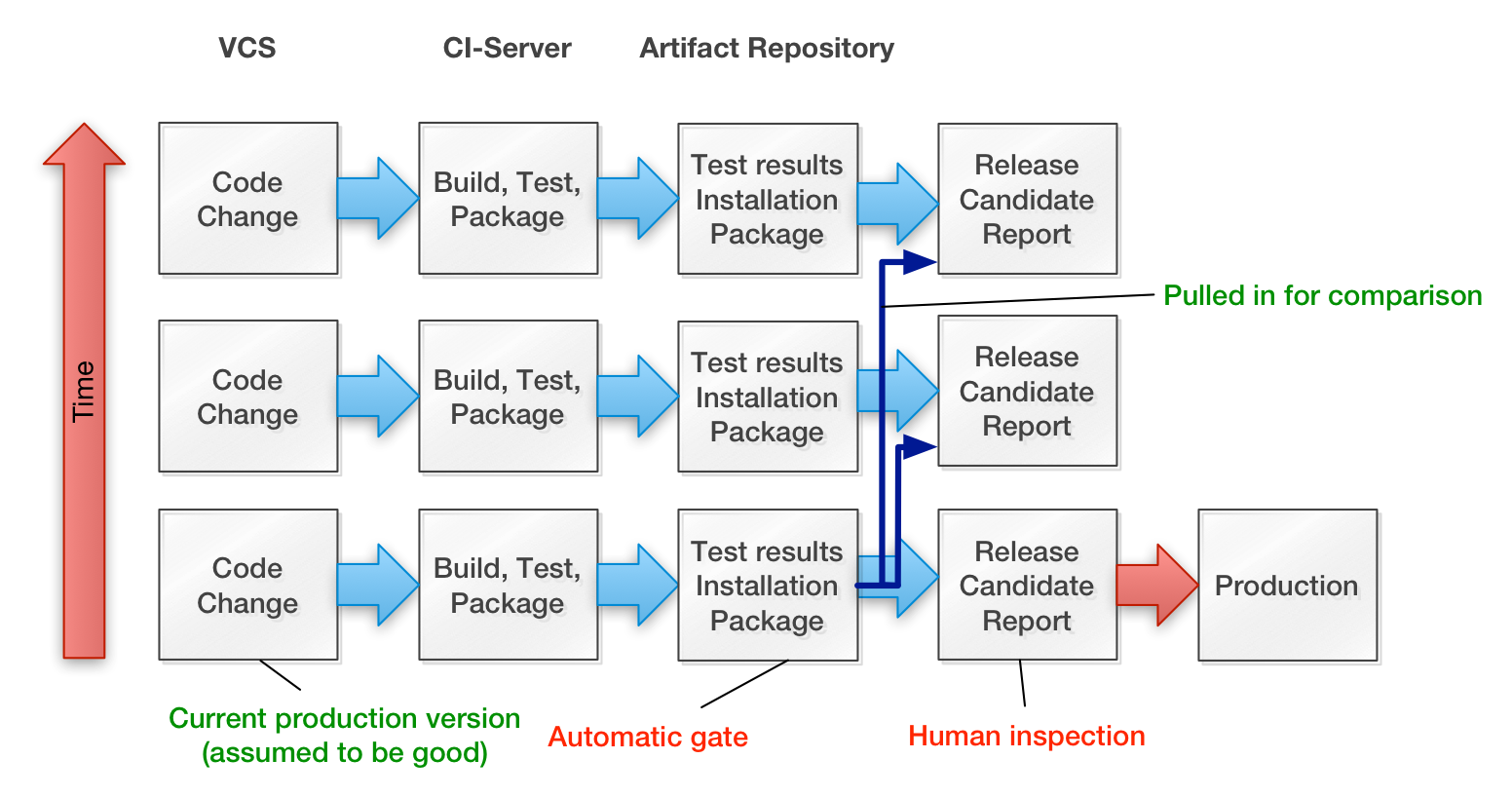
Another interesting aspect is, that in a lot of cases it is interesting to compare the results
to a baseline. Assuming that the system is up and running the current production build provides a good baseline for all sorts of metrics.
We implemented a number of such tests for our current product. As there were quite a few things to check we came up with a release checklist. The items were mostly instructions where to find a and how to evaluate the output of a particular test. The build was structured using ThoughtWorks’ Go continuous delivery product. With Go we mapped the whole build, test and release process to two pipelines, which consists of a number of stages, which in turn comprised a number of jobs. Finding all the results was cumbersome, so we decided to put all the links to these results into a dynamically created version of that checklist, which would include all the links.
This was still a bit cumbersome, so my colleague Ben Barnard implemented a candidate release report generator that actually pulled the full results into a single document. This proved especially useful for comparisons, because we presented the results of the current production build and the new build side by side as illustrated in this diagram:
The current version of our release candidate report contains the following information:
- Instructions how to interpret the report and how to release.
- A list of all our Jira tickets that had commits since the last release including their release notes (which we keep in Jira) as well as their status. For tickets that haven’t been accepted by the product owner yet, we also include a list of all commits. We added deep links to our Jira as well as to our git web-frontend, so that more information can be retrieved.
- The summary statistics for our load test results for the current production build and the new release candidate
- A graph of the average latency and error rates at different load levels for the current production version and the new release candidate
- The output of a custom diff algorithm, that we use to compare the responses of the current release candidates with the production system
- A diff that shows how the configuration file changed
Here is a generic example for a release candidate report (full html):
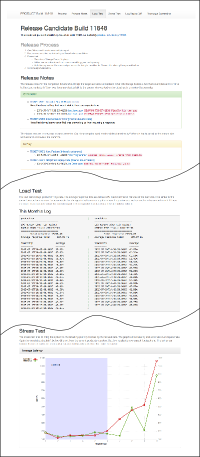
The release process now consisted of reading and reviewing a single self-documenting
document. Releasing became much simpler as a result. The release candidate report contains everything that is needed for the decision whether to replace the current version with this new release candidate.
An important move forward was to accept the fact that some tests cannot be automatically validated (at a reasonable cost) and that for those we should make human validation as simple as possible, i.e. we don’t waste brain cycles on pulling together documents, but instead use them to perform complicated pattern matching operations. Another way to look at this is, that the release candidate report is a first class artifact that summarises the build result in an actionable document.
Leave a Reply